本文共 7206 字,大约阅读时间需要 24 分钟。
计算机里面关于数值的处理自有一套体系理论,与现实生活中我们所习惯使用的不太一样。如果对其不了解,在使用计算机的过程中便可能发生一些意想不到的错误。
今天本文就来简明地介绍计算机里面的数值方面的一些知识,并用具体例子来说明可能出现的一些问题。一、一些概念
机器数:数值在计算机内部的编码,也就是实际存储的 0/1 序列。
真值:机器数想要表示的实际数值,可理解为现实生活中我们平常所用的有正负号的数。
机器数与真值的对应关系就是数值在计算机内部的编码,主要有 4 种:原码,反码,补码,移码。
原码

原码由 1 位符号位和数值部分组成,数值部分就是真值的绝对值。
特点
- 与真值的对应关系直观
- 0 的表示不唯一,有 +0(00…000) 和 -0(10…000)。
- 加减法复杂,需要判断符号
反码

反码由 1 位符号位和数值部分组成。表示一个正数时同原码;表示一个负数时,符号位不变,数值部分各位求反。
反码相对于原码并没有多大改进提升,现已不用来表示数据。
补码

补码也是由 1 位符号位和数值部分组成。表示一个整数时同原码;表示一个负数时,符号位不变,数值部分各位求反,末位加 1。
原码到补码快速转换(负数):符号位不变,从右到左的第一个1不变,其他位取反。 补码到原码(负数)转换方法同上,符号位不变,数值部分各位求反,末位加 1。也就是说符号位不变,从右到左的第一个1不变,其他位取反。
原因:按理说补码到原码应为原码到补码的逆操作,即减 1 再求反。设补码为A,则原码为 ~(A - 1),即11…111 - ( A - 1) = 11…111 - A + 1,也就是~A + 1。
因此 ~A + 1 = ~(A - 1)一个数的补码取负:连同符号位各位求反,末位加1,即从右到左的第一个1不变,其他位取反。
例如 4 位补码,[x]补 = 1011,[-x]补 = 0101
特点
-
0有唯一表示00…000,所以补码能表示的数范围比原码反码多1,表示范围为 -2n-1 ~ 2n-1-1
-
加减法符号位能直接参与运算。
-
现代的计算机整数基本都采用补码表示。
移码
移码主要用于浮点数的阶码部分,后面会讲浮点数的阶有正负,两个浮点数比较时需要比较阶码来対阶。为方便比较,将阶加上一个偏置常数使其变成正数,因为加的都是同一个偏置常数,阶的差值也是不会改变的。
所以移码就是数值本身加上一个偏置常数得到,偏置常数一般是2n-1,或者2n-1-1。
上述都是定点数的表示方法,定点数顾名思义,小数点是约定不动在一个固定位置的。定点数分为定点小数和定点整数。
-
定点整数的小数点固定在数的最右边,一般用来表示整数。
-
定点小数的小数点固定在数的左边,一般表示浮点数的尾数部分。
而浮点数的表示类似于科学计数法,它的指数部分可以变动,相应的尾数部分也跟着变化,就像小数点在浮动一样,所以叫做浮点数,浮点数后面再详解。
二、数值比较
整数分为无符号整数和有符号整数,**给定一个数,在计算机里如何存储,表示成 0/1 序列是编码的事,而对这 0/1 序列如何解释是上层软件的事情。**如c语言中可解释为有符号数和无符号数,而java中只解释为有符号数。
数值比较时,得确定类型才能比较。通常默认为有符号数相比,若出现无符号数,则按照无符号数相比。
概念模糊抽象,看下面的经典例子来理解:

第一个:两数按照有符号数相比,11…111B(-1) < 00…000B(0)
第二个:0U为无符号数,所以两数按照无符号数相比,-1的机器数为11…111,按照无符号数解释为232 -1,这时是大于0的。11…111(232-1) > 00…000(0)注:括号前的二进制表示为数值的机器数,通常由补码表示,括号里面的是c语言对机器数 按照无符号数或者有符号数 解释出来的数。
看第二个例子前补充一些知识:
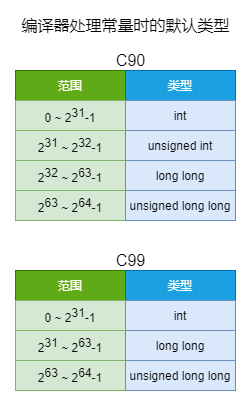
判断一个常量类型时是先将符号“踢开”,只看后面的数值在哪个区间,根据区间确定类型。
c90 和 C99 是c语言的两套标准,两套标准对常量的处理不同,下面的例子以 C90 说明

第一个:2147483647为 int 型,两边按照有符号数相比,01…111B(231 - 1) > 10…000B(-231)
第二个:2147483647为 int 型,前者带有U表示无符号数,按照无符号数相比,01…111B(231 - 1) < 10…000B(231)
第三个:2147483648为 unsigned int 型,但被强制类型转换为int型,所以按照有符号数相比,01…111B(2^31 -1^) < 10…000B(-231)
第四个:2147483648为 unsigned int 型,两数按照无符号数相比,01…111B(231 -1) < 10…000B(231)
完全理解上述几个例子后对数值比较这一块应该没问题了,在此再强调总结一番。
一个数据怎么存储成 0/1 序列是编码的事,怎么解释这个 0/1 序列是上层软件的事。
也就是说上述的数值比较中 2147483648 的机器数始终是10…000B,2147483647的机器数始终是01…111B,之所以出现不同的比较结果是因为 c 语言对它们进行了不同的解释处理。
有了上面的基础,再来看几个程序:

打印结果如上图注释,原因如下:
x 的机器数为 11…111,u 的机器数为 10…0000
所以x按照无符号数解释为232 - 1 = 4294967295,按照有符号数解释为 -1。 u按照无符号数解释为 231,按照有符号数解释为 -231由上也可以看出机器数为10…000的数,是能表示的最小整数,取负后溢出还是它本身。

这是计算数组元素和的一个函数,按照程序所设想,length 传入 0 时应该返回 0,但实际上并非如此。这个程序理论上会无限循环,实际运行时会发生数组越界导致异常。
理论上无限循环的原因:len 为无符号数,传入0时,len - 1 为 -1,机器数为11…111,按无符号数解释为232 -1,是 32 位能表示的最大整数。
前面说过,有无符号数参与比较时,两边都按照无符号数相比,所以不管 i 怎么变化,始终小于等于右边那个最大的值。当 i = 232 -1 时,下一步又会回绕到0;
但实际运行时,肯定不会有那么长的数组,所以会发生越界错误。

此函数时用来比较两个字符串str1, str2谁长,用到了库函数strlen(),其原型如上。此函数设想 str1 长时返回 1,否则返回 0;但实际上只有 str1 和 str2 长度相等时会返回 0,其他时候都返回1;
问题就出在函数strlen()的返回值是size_t,即unsigned int。也就是说比较是按照无符号数来比较的,无符号数永远是大于等于 0 的,所以只有两个串儿长度相等时会使左边式子等于 0,其他时候左边结果的机器数中肯定有非 0 位,那么按无符号数解释就会大于0,也就返回1了。
改进方法:返回语句改成return strlen(str1) > strlen(str2),直接让两个串的长度比较,而不是做减法再与0比较。
这个例子说明调用库函数也要小心,对其的返回类型,参数类型要有了解,否则可能就会出错。
三、浮点数(IEEE 754)

IEEE 754浮点数标准规定的浮点数格式如上图所示,简要解释如下:
-
符号位:1表负,0表正
-
阶码用移码表示,是一个定点整数,偏置常数是2n - 1,所以单精度的偏置常数位127,双精度的偏置常数位1023
-
尾数是一个定点小数,实际表示24位有效数字,隐含了一位 1 ,实际尾数为1.*****B
表示范围
32位单精度

负数的表示只不过是符号位发生变化,所以32位单精度浮点数能表示的极值如下:
-
最小正数:2-126
-
最大整数:(2 - 2-23) * 2127
-
最大负数:-2-126
-
最小负数:-(2 - 2-23) * 2127
64位双精度
64位双精度浮点数原理同上,能表示的极值如下
-
最小正数:2-1022
-
最大整数:(2 - 2-52) * 21023
-
最大负数:-2-1022
-
最小负数:-(2 - 2-52) * 21023
所以IEEE 754 浮点数能表示的范围如下面数轴图所示:

浮点数每个 2n-1~2n 区间内能表示的数的个数都是223个(尾数23位),而且等距。比如 1~2 之间有 223 个数,2~4 之间也有 2^23 ^个等距的数,所以浮点数表示的密度并不相等,距离0越近,密度越大。
也就是说并不是每个小数都能精确表示,当输入一个不可表示的数时,机器会将其转换为最近能表示的数。这也是为什么编写程序时不要用浮点数来进行比较,特别是相等的情况,因为你想比较的数可能无法表示,机器自动给你转换了。
特殊表示
阶码全0尾数全0
+0 或者 -0,正负看符号位
阶码全1尾数全0
+∞,-∞,正负看符号位
阶码全1尾数非0
阶码全1尾数非0,NaN(Not a Number),不是一个数,0 / 0, 0 * ∞ 等会产生NaN。
阶码全0尾数非0
从上述的数轴图中可以看出-2-126 ~ 2-126之间的数是表示不了的,引进非规格化数可解决这问题。非规格化数的尾数中的隐含位为0,阶码虽然全0,但阶还是-126。如此便在-2-126~2-126之间添加了2 * 223个数,解决了下溢问题。
同样,有了上述的基础知识,来看一些例子:

这几个题都很简单,注意几点就行:
- 精度大的转换成精度小的可能会出问题,精度小的转换成精度大的不会有问题。
- 浮点数取负直接变符号位就可。
最后一个是浮点数的加减运算问题,后面详解,在这可以举个例子简单理解下:当 d 很大 f 很小时,d + f 得到的结果就等于 d, 舍去了f,所以左边等于 0 ,右边等于 f,两边不等。
四、数值运算
按位运算和逻辑运算
这两种运算比较简单,只是要区分一下概念。
按位运算恰如其名,是对数值的位进行与或非运算。
逻辑运算的操作数只有 true 和 false,对数值的处理为非零即真。
左移右移
移位分为逻辑移位和算数移位:
-
逻辑移位:不考虑符号位,左移时高位移出,低位补0;右移时低位移出,高位补0
-
算术移位:考虑符号位,左移时高位移出,低位补0;右移时低位移出,高位补符号位;
c语言中编译器进行移位运算和CPU进行移位运算是不一样的:
-
编译器:进行实际移位,比如移动w位,实际也移动w位
-
CPU:移动 w % k ,w为所移位数,k为数据类型的位数
看下面程序帮助理解,打印结果已注释在后面

位扩展位截断
扩展分为 0 扩展和符号扩展,数据转换时,短数向长数转换时需要位扩展。
0扩展用于无符号数,在原来的数前面添足够的0即可。
符号扩展用于有符号数,在原来的数前面添足够的符号位即可。
位截断,长数向短数转化时会发生截断,规则比较粗暴简单,直接“砍掉”高位,留下低位即可。
长数的表示范围肯定大于短数,所以截断一个数可能会改变原来的值。看下面一个例子:

经过截断再扩展后 32768 变成了 -32768,所以再截断时要注意溢出问题。
计算机里整数浮点数的加减乘除运算的实际过程都很复杂,内容很多,建议直接看唐朔风的计算机组成原理第六章,数字逻辑相关书籍中加法器,乘法器等的电路实现。深入理解计算机系统对各种数值算法的理论推导。公众号内回复电子书即可获得相应书籍。下面就只说说其中我认为比较重要需要的一些东西。加减运算
现代计算机里面整数都可以看做是用补码表示的,统一了加减法,符号位也能和数值部分一起进行计算。
不论是无符号数还是有符号数,都先按照实际的机器数做运算,得到的结果再解释成相应的无符号数或有符号数。
整个计算机的运算系统都是采用模运算,得出的结果如果超出计算机表示的位数,会直接丢掉高位。
例如若两个数为a, b,对应的机器数为A, B,则a + b 相应操作为 A + B,a - b 为A + ~ B + 1。再对计算得到机器数解释成最终结果。
乘除运算
乘法主要需要考虑溢出问题,n 位数乘 n 位数,结果可能需要2n位来表示。c语言中截直接断成 n 位来实现(来自深入理解计算机系统),但经过试验结果似乎会自动扩展。
只要结果在你机器的表示范围内就会自动扩展,比如两个 short 型的数相乘结果会自动扩展成 32 位来正确表示结果,除非限定结果还是个 short 型,才会截断。
整数除法一般没有溢出问题,因为商的绝对值不会大于被除数的绝对值。
除了一种情况,有符号数中最小数除以-1,例如 int 型的情况:-2147483648 / -1 便会溢出,结果还是 -2147483648 本身。
在这说点 c 里面一些有趣的东西,可以算是bug吧。上述说的有符号数中的最小数,即机器数为10…000的数(设为s)取负后还是它本身,这是没问题的,机器数也的确是相同的。所以按理说 s = -s。这在32位int型,64位long long的情况下成立,但是在short情况下不成立。所以 c 里面关于数值的东西有许多奇奇怪怪的东西,诸位感兴趣可以去尝试。
常量乘除
乘除法运算所花的时间远远多于移位加减运算的时间,因此,编译器处理变量与常量乘除时会以移位,加法,减法的组合运算来代替乘除法。
来看一个具体例题:x为一整形变量,现要计算55 * x,给出一种计算表达式使得所用的时钟周期最少。

题目很简单,主要是想说明怎么转换。
乘以 2n 相当于左移 n 位,除以 2n 相当于右移 n 位。
**左移需要注意高位的溢出问题,而右移则需要注意舍入问题。一般的舍入规则是向0舍入,但用移位来实现除法是向下舍入的。**对于正数来说没什么问题,向下舍入就是向0舍入。但是负数就有问题了,向下舍入并不是向0舍入,需要校正。为什么移位来实现除法是向下舍入的呢,正数应该很好理解,右移之后丢掉移出的小数部分,数值自然变小了。如果是负数,右移之后丢掉小数部分数值不应该变大吗?但别忘了负数在计算机里由补码表示,它跟真值对应的关系是要求反的,所以换成真值后会发现数值依然是变小的。
来看一个例子理解向下舍入,应该会更清楚
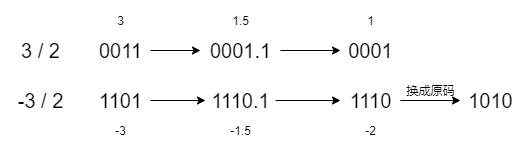
如何校正呢?
既然负数也是向下舍入,那么在它移位之前先给它加上一个偏移量让它变大点,那么移位后舍入不就正确了。如果右移n位,这个偏移量就是2n-1,原来是 x / 2n,现在是(x + 2n - 1) / 2n = x / 2n + (2n-1 / 2n);相当于加了一个"极限小数"来校正。
这个数可以在十进制下来理解,比如移动一位也就是一位小数的情况下,-2.1,-2.9都要舍入到-2,应该怎么操作呢?将两个数都加上一个0.9就行了,这里0.9就是十进制一位情况下的一个极限小数,换成二进制同理,二进制 n 位的一个"极限小数"就是2n-1 。
浮点数运算
加减法
1、対阶
只有阶数相等,尾数才能直接相加减。
対阶原则:小阶对齐大阶,阶小的尾数右移,右移尾数为阶差。注: 右移时注意隐含位 1 也要一起参与移位,为保证精度,低位移出的位不要丢掉,后续参与尾数加减。
2、尾数加减
尾数是由定点原码小数表示,这里没有符号位,所以加减就是普通的二进制加减法。这里注意隐含位和対阶时移出的附加位也要参与运算。
3、规格化
上述尾数加减后得到结果可能五花八门,千奇百怪,需要规格化变成 IEEE 754 的标准形式。**简单说来就是把尾数变成1. **B的形式,然后相应的调整阶码。小数点的位置与阶码息息相关,小数点浮动了,阶码当然也要相应变化。
4、结果舍入
対阶和尾数规格化的时都可能右移,为保证精度,会将移出的位保留下来参与中间运算,得出最终结果后再舍入。IEEE 754规定至少保留 2 位,紧跟在尾数右边的叫做保护位(guard),保护位右边的叫做舍入位(round),为提高精度,舍入位右边还有一位粘位(sticky)。只要粘位右边有任何的非0数就置1,否则置0。
5、阶码溢出判断
结果的阶码全 1 表上溢,产生异常或者结果置为∞。
结果的阶码全 0 表下溢,产生异常或者结果置0这就能解释前面为什么 (d + f ) - d 不一定等于 f ,d 如果很大,f 很小,対阶时f 看齐d,尾数可能一直右移导致有效位没有了变成了全0,再进行尾数加减时 d 值不变。所以左边等于0,右边等于 f,两者不等。
乘除法
浮点数乘法运算过程类似加减法,主要区别在于乘除法不用対阶,其他过程基本一样。也好理解,就像我们平时用科学计数法做算数时,加减法那肯定是需要指数相等,尾数才能相加减;而乘除法时可以直接尾数与尾数运算,指数与指数运算,一个道理。
计算机里面有关数值的问题有很多,不仅计算机本身有一套规则,各语言的编译器也有自己的规则,里面的弯弯绕绕很多,会造成各种奇奇怪怪的问题。本文也只是捡重点做简要介绍,系统的理解还是去看书吧,这里推荐深入理解计算机系统,里面数值的基础理论很系统;唐朔风的计算机组成原理对运算这一块而讲的比较详细;袁春风老师的计算机系统基础也很经典,比较薄容易读下去。本文很多地方的例子就是采用她书上或者PPT中的例子。然后再看看数字逻辑的相关书籍了解了解加法器乘法器等的电路实现来加深理解。
好啦本文就到这里,如果哪有错或不足,还请大家批评指正;
喜欢本文的朋友还请点个赞支持一下,关注公众号Rand_cs可获取更多关于系统的精品文章,还有关于计算机的各类电子书,总能找到你需要的,赶快关注吧

转载地址:http://hpiv.baihongyu.com/